Employee Survey Analysis (ESA) Scripts
With this paper of our, we have peculiarly worked on one of the application of Data Analysis. We have proposed a fresh method for happening out valuable information out of the clump of natural informations utilizing Python and NLTK libraries. We have processed the Remarks of the assorted Employees of a Company in the signifier of Raw Data. Each Remark follows different stairs such as Cleansing which removes all the errors in the remarks made by the user, Taging which tags word harmonizing to the different types of verbs or adjectives used in the remarks, Lumping which includes choosing a perticualr phrase out of the cleansed remark by usage of a appropriate grammar regulation, Category Generation which includes different types of class generated for the words which can be used for bring forthing different class user remarks. This includes the usage of Python as a tool where NLTk is added as a Natural Language Processor which is used for different sorts of linguistic communications. You may happen the elaborate account about our methodological analysis in the ulterior parts of this paper.
Introduction
With the growing of IT sector over the past few old ages, informations handling and its analysis had become really hard. Many companies trades with a big sum of informations and they have purchased different tools from different companies like IBM, Microsoft, etc for informations storage and its analysis. Data Analysis fundamentally provides us the method to pull out some valuable information out of some natural facts. It contains several Fieldss which are required to be undertaken such as taking all the errors, change overing it into that signifier which our tool can understand, saying regulations for it usage, happening the results and take supportive actions on the footing of these results. The field of Data Analytics is pity huge and have many attacks related to informations extraction and mold and in this paper we will be discoursing on the one of the of import application of Data Analytics.
Order custom essay Employee Survey Analysis (ESA) Scripts with free plagiarism report
 450+ experts on 30 subjects
450+ experts on 30 subjects
 Starting from 3 hours delivery
Starting from 3 hours delivery
Let us better understand what Data Analysis is with illustration of a individual named Lee who had a wont of composing dairy. He started observing each and every incident of his life get downing from his birth boulder clay now. With the class of clip, he have written a batch of information about himself which reflects different phases of his life. Suppose if another individual goes through each and every incident of Lee 's life and analysis what he used to wish when he was below 10 old ages of age or which portion of his life was unforgettable. This analysis of the natural information and happen out the valuable information out of it is categorized with the term Data Analytics. I think now we are in a place to understand the relevant nomenclatures used in this paper. So I would wish to depict the existent methodological analysis of our research paper.
A Brief Methodology
This paper demonstrates a novel method which help user to pull out utile information from the clump of a natural information. It includes a method/ codes which include the usage of set of categories and maps which help in pull outing a utile information out of input informations. There are many utile maps which help in pull outing information that are included here. Some of them may be named as, Tokenizer, Taggers, Chunkers, Stemmers, Transformation of Chunkers and Taggers and many more. These methods or categories work on the tool Named as Python 2.7.6 which is required to be downloaded and good configured in the system. Every Code that is executed required to be imported through assorted bundles present in the library. In this undertaking, we have processed the informations and produced the different class out of it and through that we have extracted what user really meant to state in his/her remarks. You may happen the elaborate account as what this paper is all approximately in ulterior portion.
Python is considered as a high degree linguistic communication, a degree in front of C and C++ . It is fundamentally developed for developing applications or books for transforming different signifiers of linguistic communications like English, French, German and many more. Python have a alone characteristic which differentiate it from other linguistic communications like C, C++ or Java is that it uses white infinite indenture instead than curly brackets. Presently, the latest version of python in the market is Python 3.4.1 was released on May 18th, 2014. But we have used Python 2.7.6.
NLTK is described as Natural Language Tool Kit. It comprises of library files in different linguistic communications that Python may utilize for informations analysis. One is required to import the NLTK bundle in the Python Shell so that its library files can be used by the coder. NLTK includes several characteristics like graphical presentation of informations. Several books have been published on the alien belongingss and installations of NLTK which clearly explains things off to any coder who is either novice with python or NLTK or merely an expert. NLTK finds several applications in research work when it comes to Natural Language Processing. It helps in treating text in several linguistic communications which itself is a large positive for modern research workers.
Implementation of Employee Survey Analysis ( Esa ) Scripts
In Today 's universe of Globalization and competitions, It is the tendency which is followed by every company to form a Engagement and Exit Survey for its employee within the organisation to happen out the grounds why people wants to fall in or go forth their company. When any individual leaves any company, he/she is required to make full an online study that comprises of assorted Fields which might be the grounds for his go forthing the Organization. In that study, the inquiries might be in assorted signifiers like Check Boxes, Scroll List, Text field, etc. It is pity easy to enter and analysis those inquiries which involve replying through Checkboxes or Scroll List but state of affairs becomes really feverish for the individual who is analysing that informations if the reply is recorded through Text fields or Text Paragraph. When speaking about manually reading, the individual, who is reading that informations, will be required to travel through each and every employees remarks to happen what were the grounds why they have left the occupation. Each company comprises of 1000s of employees and it is really common in industries that people moves from one organisation to another organisation. So, maintaining the path of all those employees by merely manual reading is a tough undertaking.
Figure 1– A Screen Shot of Employee Exit Survey [ 1 ]
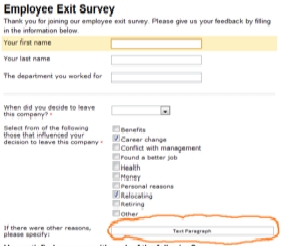
Each company spends a batch of money and resources on their employees on their preparation and growing and hence, wants to happen the grounds why their best employees are go forthing them. Therefore, we are in an pressing demand of something which can assist us happening the grounds why any individual is go forthing his/her organisation. Although, there are several tools in the market by some singular companies like IBM. But the major point is they all are paid and therefore, require a batch of money to invested to buy them. In comparing with these paid tools, these Python Script are unfastened beginning and are free of cost. Any organisation can besides do alterations in the books harmonizing to its demand. Hence, it is supplying us the best ground why to choose for ESA Scripts.
ESA Scripts performs following actions as specified below: -
- It corrects all the Spelling Mistakes.
- It corrects all the Repeated Words.
- It performs Lemmatization, Stemming and Tokenization of Data.
- It performs Antonyms and Synonym Operations on words.
- It find out what sort of Verb, Noun or Adjective is used by the Employee.
- It generates Phrases depending upon the type of Grammar Rule one select.
- Removal of Stop Words.
- Encoding and Decryption of Special Stop Words.
- Removal of ASCII Codes.
There are many more of import operations which comes under these above specified operations which are discussed subsequently as their functions comes.
First of all, Remarks of different employees are taken in a individual Column of a CSV file and read line wise. Each Remark comprises of different paragraph holding different Spelling errors, repeated characters in a word and many more errors which are required to be removed before we can happen out what individual meant in his/her grounds for go forthing his/her occupation.
All the files are required to be stored by.py extension and all the of import methods or categories are required to be defined in a individual library file so that when utilizing those maps and classes we can import them in a spell and utilize them to make whatever we like to make. These methods/classes are defined in library file named as CustomClassLibrary.py and this file is required to be executed at the top before utilizing any of the map or category so that these categories work consequently whenever they are called in the chief book.
There is yet another of import thing that we are required to take attention of. You must either topographic point all you scripts in the current on the job directory or you must supply the way where you have placed your books. It is extremely required and if we do non supply the way of our books decently so it will be traveling to demo mistakes which will return an mistake that current file do non be in our directory.
Figure-2Block Diagram Representing Various Processes to be followed
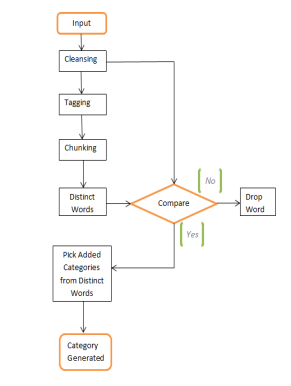
This Purpose has been divided into 3 Class which are as follows:
- a. Cleansing.
- b. Tagging and Chunking .
- c. Category Generation.
The above described description can be better explained by the figure given below.
Cleansing, as its name suggests includes the methods which help in cleaning the information which the user has provided. It includes those methods or maps by which one can tokenize informations, correct the spellings, take all the perennial words like if any user wrote ‘love’ as ‘llooovvvee’ in a really passionate manner. So they are required to be corrected. There are several Abbreviations that people wrote which are required to be changed to their normal word signifier. Then there are several stop words in the sentences which do non lend much to the significance of that sentence are hence required to be removed from that sentence. The process of this is explained as below.
First of wholly, we break Paragraph into Sentences and in that process some of the words are changed into ASCII Codes which created job when we further run the procedure on them and are required to be removed through strip_unicode bid. After taking ASCII Codes we tokenize Sentences into words.
Now, explicating each class in item below.
Figure-3Measure wise Explanation for Above Process
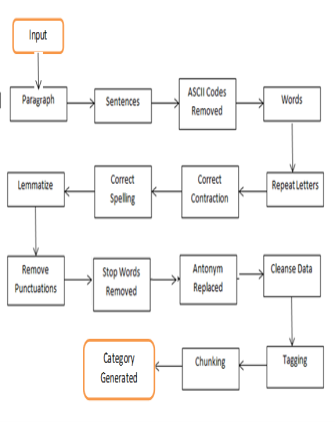
These words are processed and all the perennial words like “looovvee” are changed to “love” by utilizing repetition replacer map. After that all the short signifiers or the Abbreviations are changed to their full signifiers. All the spelling errors are required to be corrected before continuing farther. This map is imported utilizing import bid and all the methods are required to be defined in our library file named as CustomClassLibrary.py
After rectifying all of our spelling errors, we lemmatize our word if they are found to be of Noun, Adjective or Verb. For any other class of words, it traveling to go through the word as it is. After that all the punctuations are removed such as Commas, Exclamation grade, Full Stops, etc.
Here, now we are required to code some of the particular words so that they can be used in approaching procedure. We will be coding some of the words and them taking stop words from that list of words. All those word which do non assist in analysing the sentences like can, could, might, etc are removed from the list of words. Once, Stop words removed, we once more decrypt those particular words once more so that they can be processed now. At this measure, we have got the list of words which are traveling to be passed to make Antonym of words which appears after “not” word.
For Example, “let’s” , “not” , “uglify” , “our” , “code” is changed to “let’s” , “beautify” , “our” , “code” . Therefore, we are at that place with our Cleansed Data.
Tagging is a procedure of assigning different tickets to the word in conformity with the portion of address tagging. For this, we have used Classifier based POS tagger [ 5 ] [ 10 ] which is rather a good tagger. When calculated, its efficiency comes out to be over 90 % which is rather good. For labeling, we passed the information word wise and happen out to which portion of address class it belongs. Either it is a noun or it is a verb or adjectival like vise.
We are making labeling in order to bring forth labeled word from where we can make a grammar regulation so that from them, all the words which comes, forms a meaningful phrase and therefore can be wrote in different file.
Grammar Rule and Unitization
This Chunk Rule can be described as the phrase formed will get down with optional Adverb or Determiner or any sort of Noun or any sort of Verb followed by any sort of optional Verb followed by optional any word followed by any sort of optional Adjective and stoping with as many figure of any sort of Adjective or any sort of Noun.
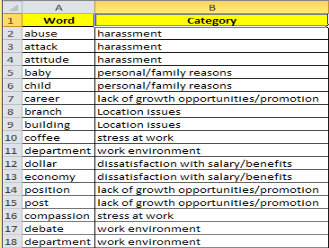
For Category Generation, we have selected those set of tokenized words which are generated from chunked end product. These words are written individually in different file and we manually create class for that. Like if “salary” appears in the file so we have created its class as “salary problem” likewise if “family” appears in the word so we generated its class as “Personal Issues” . Once this file is created so we compare each and every word of the file and if we find that word in our distinguishable words file so we are traveling to bring forth that class for that word.
Figure-3Distinct Categories defined for Chunked words
Once the class is generated, this class is used to bring forth the consequences for the different remarks made by user. It is here shown in the figure below.
Figure-4Classs Generated for different Employees remarks
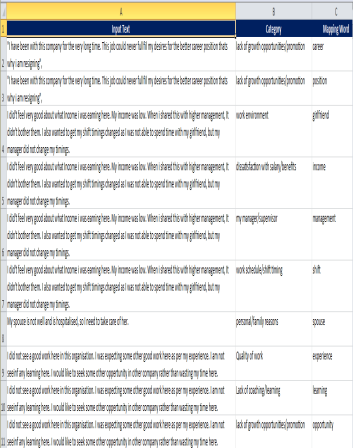
We can make sentimental analysis utilizing this application.
Sentimental Analysis - This is a procedure of analysing the sentiments of a individual, be it positive, negative or assorted emotions.
We can utilize the same application for other spheres as good like battle of an employee with the organisation.
Decision
This Paper provides a advanced thought which helps in cut downing the human attempts as individual who is analysing the information of assorted employees who had left every bit now, is non required to travel through each and every employee’s remarks. Therefore, by running these books we will be able to bring forth what an employee is speaking about, what are the assorted causes which he found in the company which forced him to vacate. Hence, the value of this merchandise goes up when you think analysing the information of different users of different states following different linguistic communications.
References
- hypertext transfer protocol: //123facebooksurveys.com/wp-content/uploads/2011/10/employee-exit- interview-1.png.
- hypertext transfer protocol: //en.wikipedia.org/wiki/Python_ ( programing language ) .
- hypertext transfer protocol: //www.python.org/download/releases/3.4.1/ .
- hypertext transfer protocol: //www.nyu.edu/projects/politicsdatalab/workshops/NLTK_Presentation.pdf.
- hypertext transfer protocol: //www.packtpub.com/sites/default/files/3609-chapter-3-creating-custom-corpora.pdf.
- hypertext transfer protocol: //caio.ueberalles.net/ebooksclub.org__Python_Text_Processing_with_NLTK_2_0_Cookbook.pdf.
- hypertext transfer protocol: //fjavieralba.com/basic-sentiment-analysis-with-python.html.
- hypertext transfer protocol: //www.ics.uci.edu/~pattis/ICS-31/lectures/tokens.pdf
- hypertext transfer protocol: //nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html.
- hypertext transfer protocol: //www.monlp.com/2011/11/08/part-of-speech-tags/
- hypertext transfer protocol: //danielnaber.de/languagetool/download/style_and_grammar_checker.pdf.
- hypertext transfer protocol: //www.eecis.udel.edu/~trnka/CISC889-11S/lectures/dongqing-chunking.pdf.
Cite this Page
Employee Survey Analysis (ESA) Scripts. (2018, Aug 16). Retrieved from https://phdessay.com/employee-survey-analysis-esa-scripts/
Run a free check or have your essay done for you
