Effective Pattern Discovery for Text Mining
Abstract
Text excavation has been an ineluctable information excavation technique. There are different methods for text excavation, One of the most successful will be mining utilizing the effectual patterns. Datamining has become an adaptative method for recovering utile information in big database. This paper gives the brief thought about the text excavation by find of effectual forms. As our system trades with form ( phrase ) based and which overcomes the term based method ( attack ) .The procedure of updating unambiguous can be referred as pattern rating. This attack can better the truth of measuring term weights because discovered forms are more specific than the whole papers. In our proposed system effectual pattern find technique include the procedure of form deploying and form evolving, for happening the relevant information.
Keywords: Text excavation, Text Classification, Pattern Deploying, Pattern Evolving.
Order custom essay Effective Pattern Discovery for Text Mining with free plagiarism report
 450+ experts on 30 subjects
450+ experts on 30 subjects
 Starting from 3 hours delivery
Starting from 3 hours delivery
I. Introduction
Text Mining is the find by computing machine of new, antecedently unknown information, by automatically pull outing and associating information from different written resources, to uncover otherwise `` concealed '' meanings. Knowledge find can be viewed as the procedure of nontrivial extraction of information from big databases, information that is implicitly presented in the information, antecedently unknown and potentially utile for users. Data excavation is hence an indispensable measure in the procedure of cognition find in databases. In the past decennary, a important figure of informationsmining techniques have been presented in order to execute different cognition undertakings. These techniques include association regulation excavation, frequent itemset excavation, consecutive form excavation, maximal form excavation, and closed form mining text excavation is the find of interesting cognition in text papers. It is a ambitious issue to happen accurate cognition ( or characteristics ) in text papers to assist users to happen what they want. With a big figure of forms generated by utilizing information excavation attacks, how to efficaciously utilize and update these forms is still an unfastened research issue. In this paper, we focus on the development of a cognition find theoretical account to efficaciously utilize and update the discovered forms and use it to the field of text excavation.
The advantages of term based methods include efficient computational public presentation every bit good as mature theories for term weighting, which have emerged over the last twosome of decennaries from the IR and machine acquisition communities. However, term based methods suffer from the jobs of lexical ambiguity and synonymity, where lexical ambiguity means a word has multiple significances, and synonymity is multiple words holding the same significance. The semantic significance of many discovered footings is unsure for replying what users want.
Finding effectual and utile forms is remains a disputing task.Our proposed work presents an effectual form find technique, which foremost calculates ascertained specificities of forms and so evaluates term weights harmonizing to the distribution of footings in the ascertained forms instead than the distribution in paperss for work outing the misunderstanding job. It besides considers the influence of forms from the negative preparation illustrations to happen equivocal ( noisy ) forms and seek to cut down their influence for the low-frequency job. The procedure of updating equivocal forms can be referred as pattern development. The proposed attack can better the truth of measuring term weights because discovered forms are more specific than whole paperss.
II. Related Work
Here we are suggesting a form taxonomy theoretical account. Other different form excavation methods are Sequential forms, Sequential closed forms, frequent itemsets, Frequent closed point sets. All these provide similar consequences but on depending on preciseness and remember our method stand manner apart. Recently, we have seen the ebullient visual aspect of really big heterogenous full-text papers aggregations, available for any terminal user. The assortment of users’ wants is wide. The user may necessitate an overall position of the papers aggregation: what subjects are covered, what sort of paperss exists, are the paperss someway related, and so on. On the other manus, the user may desire to i¬?nd a specii¬?c piece of information content. At the other extreme, some users may be interested in the linguistic communication itself. A common characteristic for all the undertakings mentioned is that the user does non cognize precisely what he/she is looking for. Hence, a information excavation attack should be appropriate, because by dei¬?nition it is detecting interesting regularities or exclusions from the informations, perchance without a precise focal point.
Surprisingly plenty, merely a few illustrations of informations excavation in text, or text excavation, are available. Their attack, nevertheless, requires a significant sum of background cognition, and is non applicable as such to text analysis in general. An attack more similar to ours has been used in the PatentMiner System for detecting tendencies among patents. In this paper, we show that general informations excavation methods are applicable to text analysis undertakings ; we besides present a general model for text excavation. The model follows the general cognition find ( KDD ) procedure.
III. Proposed System
- Documents Preprocessing
- Pattern Taxonomy Modeling
2.1 Frequent and closed forms
2.2 Pattern Taxonomy
2.3 Closed Sequential Patterns
- Pattern Deploying
3.1 Representation of Closed Forms
3.2 D-Pattern Mining
- Inner Pattern Evolution
Systen Architecture
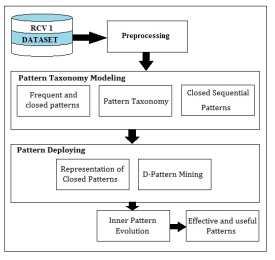
First choose the RCV1 dataset for Document Preprocessing.After preprocessing papers goes through pattern taxonomy mold and patterndeploying.pattern taxonomy patterning consist of
Frequent and closed form, pattern taxonomy and closed consecutive pattern.after the completion of pattern taxonomy it goes through the form deploying procedure by utilizing D form excavation algorithmwe found the interior pattern rating.
Finally we got the effectual forms for acquiring utile information from the papers.
1. Documents Preprocessing
Documents preprocessing is required to happen existent footings contained in the papers. Preprocessing removes unwanted text from papers, which reduces the size of paperss. Preprocessing involves following stairss:
1 . Stop-word remotion
Stop-words are those words that occur often, but holding no conceptual significance. For illustration: “a” , “at” , ”is” , ”of” , ”the” etc. There are 100s of halt words, which increase the size with no conceptual significance.
2. Non-word remotion
Non-words are punctuation Markss, which have to be removed from papers. These words besides occurs often and holding no conceptual significance.
3. Steming
Stemmingis the procedure for cut downing inflected ( or sometimes derived ) words to their root, base orrootform—generally a written word signifier. Steming is achieved utilizing Porter’s Algorithm.
A preprocessed papers is so used for farther processing.
2. Pattern Taxonomy Modeling
All paperss are split into paragraphs. So a given papersvitamin Doutputs a set of paragraphs PS (vitamin D) . Let D be a preparation set of paperss, which consists of a set of positive paperss, D+; and a set of negative paperss, D-. Let T = { T1, T2……tm} be a set of footings ( or keywords ) which can be extracted from the set of positive paperss, D+.
2.1 Frequent and Closed Forms
Given a termset Ten in papers vitamin D,Tenis used to denote the covering set of Ten forvitamin D, which includes all paragraphs dpa?S PS (vitamin D) such thatTen?displaced person, i.e. ,Ten= { dp|dpa?S PS (vitamin D) } Its absolute support is the figure of happenings of X in PS (vitamin D) , that is supa( Ten ) =|Ten| . Its comparative support is the fraction of the paragraphs that contain the form, that is supR( Ten ) = |Ten| / PS (vitamin D) . A termset Ten is called frequent form if its swallowR( or supa) & A ; gt ; = min_sup, a minimal support. Given a termset X, its covering setTenis a subset of paragraphs. Similarly, given a set of paragraphs Y ?PS (vitamin D) , we can specify its termset, which satisfies termset Y= { t| ?displaced persona?SYttrium& A ; gt ; = t a?Sdisplaced person}
The closing of X is defined as follows:
Chlorine( Ten ) =termset (Ten)
A form X ( atermset ) is called closed if and merely if X =Chlorine( Ten ) . Let X be a closed form. We can turn out that swallowa( Ten1) & A ; gt ; swallowa( Ten ) For all forms X1a?S X ; otherwise, if, swallowa( Ten1) = swallowa( Ten ) we have,X1=Ten.
where, supa(X1) and swallowa(Ten) are the absolute support of formX1andTen, severally.
2.2 Pattern Taxonomy
Forms can be structured into a taxonomy by utilizing theis-a ( or subset ) relation. A term with a higher tf*idf value could be meaningless if it has non cited by some d-patterns ( of import parts in paperss ) . The rating of term weights ( supports ) is different to the normal term-based attacks. In the term-based attacks, the rating of term weights is based on the distribution of footings in paperss. In this research, footings are weighted harmonizing to their visual aspects in discovered closed forms.
2.3 Closed Sequential Patterns
Given a form ( an ordered termset ) Ten in papers vitamin D,Tenis still used to denote the covering set of X, which includes all paragraphPSa?S PS (vitamin D) . such that X ?ps, i.e. ,Ten= { ps|psa?S PS ( vitamin D ) ; X ?ps } .
Its absolute support is the figure of happenings of X in PS ( vitamin D ) , that is supa( Ten ) = |Ten| .
Its comparative support is the fraction of the paragraphs that contain the form, that is, swallowR( Ten ) = |Ten| / PS (vitamin D) .
A consecutive form X is called frequent form if its comparative support ( or absolute support ) & A ; gt ; =min_sup, a minimal support. The belongings of closed forms can be used to specify closed sequential forms. A frequent consecutive form X is called closed if non ? any ace form X1of X such that swallowa( X1 ) =supa( Ten ) .
2. Pattern Deploying
In order to utilize the semantic information in the form taxonomy to better the public presentation of closed forms in text excavation, we need to construe discovered forms by sum uping them as d-pattern in order to accurately measure term weights ( supports ) . The rational behind this motive is that d-patterns include more semantic significance than footings that are selected based on a term-based technique ( e.g. , tf*idf ) . Asa consequence, a term with a higher tf*idf value could be meaningless if it has non cited by some d-patterns ( some of import parts in paperss ) . The rating of term weights ( supports ) is different to the normal term-based attacks. In the term-based attacks, the ratings of term weights are based on the distribution of footings in paperss. In this research, footings are weighted harmonizing to their visual aspects in discovered closed forms.
3.1 Representations of Closed Forms
It is complicated to deduce a method to use ascertained forms in text paperss for information filtrating systems. To simplify this procedure, we foremost review the composing operation a?? defined. Let P1and P2be sets of term-number braces. P1a??P2is called the composing of P1and P2which satisfies:
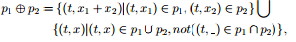
Where is the wild card that matches any figure. For the particular instance we have p a?? O= P ; and the operands of the composing operation are interchangeable. The consequence of the composing is still a set of term-number braces.
Formally, for all positive paperss vitamin DIa?S D+, we foremost deploy its closed forms on a common set of footingsThyminein order to obtain the undermentioned d-patterns ( deployed forms, non-sequential leaden forms ) :
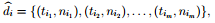
Where Tijin brace ( Tij, Nij) denotes a individual term and Nijis its support in vitamin DIwhich is the entire absolute supports given by closed forms that contain Tsij; or nijis the entire figure of closed forms that contain Tsij
4. Inner Pattern Evolution
In this Module, we discuss how to reshuffle supports of footings within normal signifiers of d-patterns based on negative paperss in the preparation set. The technique will be utile to cut down the side effects of noisy forms because of the low-frequency job. This technique is called interior form development here, because it merely changes a pattern’s term supports within the pattern.A threshold is normally used to sort paperss into relevant or irrelevant classs. Using the d-patterns, the threshold can be defined of course as follows:
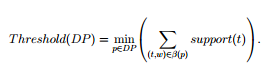
A noise negative papers neodymium in D-is a negative papers that the system falsely identified as a positive, that is weight (neodymium) & A ; gt ; = Threshold ( DP ) . In order to cut down the noise, we need to track which d-patterns have been used to give rise to such an mistake. We call these forms wrongdoers ofneodymium.
An wrongdoer of neodymium is a d-pattern that has at least one term inneodymium. The set of wrongdoers of neodymium is defined by:
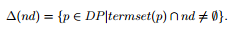
The chief procedure of inner pattern development is implemented by the algorithm IP Evolving. The inputs of this algorithm are a set of d-patternsDisplaced person, a preparation set D = D+U D-.
IV. Decision
Hence we conclude here that the proposed system trade with effectual form find utilizing pattern deployement and form germinating to polish the ascertained form in text papers. Previous informations excavation technique used the association regulation excavation, frequent itemset excavation, consecutive form excavation, maximal form excavation, and closed form mining.It have the job of low frequence and deficiency of power in support.Hence, misunderstandings of forms derived from informations mining techniques lead to the uneffective public presentation.
In this proposed system, an effectual form find technique has been proposed to get the better of the low frequence and misunderstanding jobs for text excavation. The proposed technique uses two procedures, pattern deploying and form evolving, which helpful in happening the effectual form sequences for big text paperss. The experimental consequences show that the proposed theoretical account performs non merely other pure informations mining-based methods and the construct based theoretical account, but besides term-based theoretical accounts.
Mentions
- Y. Huang and S. Lin, '' Mining Sequential Patterns Using GraphSearch Techniques '' , Proc. 27th Ann. Int’l Computer Software and Applications Conf. , pp. 4-9, 2003.
- S.-T. Wu, Y. Li, Y. Xu, B. Pham and P. Chen, `` Automatic Pattern-Taxonomy Extraction for Web Mining '' , Proc. IEEE/WIC/ACM Int’l Conf. Web Intelligence 2004.
- C. Zhai, A. Velivelli, and B. Yu, '' A cross-collection mixture theoretical account for comparative text excavation '' In Proceedings of the 2004 ACM SIGKDD international conference on Knowledge find and information excavation.
- S.T.Wu, Y. Li, and Y. Xu, '' An effectual deploying algorithm for utilizing pattern-taxonomy '' , In iiWAS’05, pages 1013–1022,2005.
- Qiaozhu Mei and ChengXiangZhai [ Department of Computer Science ] , '' Detecting Evolutionary Theme Patterns from Text An Exploration of Temporal Text Mining '' , 2006.
- S.-T. Wu, Y. Li, and Y. Xu, '' Deploying Approaches for Pattern Refinement in Text Mining, '' Proc. IEEE Sixth Int’l Conf. Data Mining ( 2006.
- N. Jindal and B. Liu. '' Identifying Comparative Sentences in Text Documents, Proc. 29th Ann. Int’l ACM SIGIR Conf. Research and Development in Information Retrieval '' , 2006.
- Hiroki Arimura [ Department of Informatics, Kyushu University, Fukuoka 812 { 8581, Japan PRESTO, Japan Science and Technology Corporation ] , '' Text Data Mining with Optimized Pattern Discovery '' ,2006.
- P. Tan, M. Steinbach, and V. Kumar. `` Introduction to Data Mining, Pearson, Boston '' , 2006.
- '' Deploying Approaches for Pattern Refinement in Text Mining '' , Sheng-Tang Wu Yuefeng Li YueXu, ( 2006 ) .
- '' Knowledge find utilizing pattern taxonomy theoretical account in text excavation '' , Sheng-Tang Wu,2007
- Andrew J. Torget, RadaMihalcea, Jon Christensen, Geoff McGhee, `` Maping texts: uniting Text-mining and Geo-Visualiazation to unlock the research potency of historical newspapers '' ,2010.
- I. H. Witten, E. Frank, and M. A. Hall, `` Data Mining, Morgan Kaufmann '' , Burlington, MA, 2011.
- D. K. Hong, S. H. Yook, M. Y. Kim, Y. J. Park, H. S. Oh, D. H. Nam, and Y. B. Park, `` A Structural Analysis of Sanghanron by Network Model- Centered on Symptoms and Herbs of Taeyangbyung Compilation in Sanghanron, '' Korean Oriental Med,2011.
- JiHoon Kang, Dong Hoon Yang, Young Bae Park, and Seoung Bum Kim, '' A Text Mining Approach to Find Patterns Associated with Diseases and Herbal Materials in Oriental Medicine '' ,2012
- Mrs.K. Mythili, Professor, Department of Computer Applications, Hindusthan College of Arts and Science, Coimbatore -6, Tamilnadu. India '' , A Pattern Taxonomy Model with New Pattern Discovery Model for Text Mining '' ,2012.
- KavithaMurugeshan, Neeraj RK, " Detecting Forms to Produce Effective Output through Text Mining Using Naive Bayesian Algorithm '' ,2012.
Cite this Page
Effective Pattern Discovery for Text Mining. (2018, Aug 04). Retrieved from https://phdessay.com/enhanced-pattern-discovery-for-text-mining-using-effective-pattern-deploying-and-pattern-evaluation-techniques/
Run a free check or have your essay done for you
