A Survey on Different Architectures Uses in Online Self Testing for Real Time Systems
A Survey on Different Architectures Used in Online Self Testing for Real Time Systems
I.ABSTRACT
On-line self-testing is the solution for observing lasting and intermittent mistakes for non safety critical and real-time embedded multiprocessors. This paper fundamentally describes the three programming and allotment policies for online self-testing.
Order custom essay A Survey on Different Architectures Uses in Online Self Testing for Real Time Systems with free plagiarism report
 450+ experts on 30 subjects
450+ experts on 30 subjects
 Starting from 3 hours delivery
Starting from 3 hours delivery
Keywords-components:MPSoC, On-line self-testing, DSM engineering
II.INTRODUCTION
Real-time systems are really of import parts of our life now a twenty-four hours to twenty-four hours. In the last few decennaries, we have been studied the clip facet of calculations. But in recent old ages it has increase exponentially among the research workers and research school. There has been an oculus catching growing in the count of real-time systems. Bing used in domestic and industry production. So we can state that real-time system is a system which non merely depends upon the rightness of the consequence of the system but besides on the clip at which the consequence is produced. The illustration of the real-time system can be given as the chemical and atomic works control, infinite mission, flight control systems, military systems, telecommunications ; multimedia systems and so on all make usage of real-time engineerings.
Testing is a cardinal measure in any development procedure. It consists in using a set of experiments to a system ( system under trial ? SUT ) , with multiple purposes, from look intoing right functionality to mensurating public presentation. In this paper, we are interested in alleged
black-box conformity testing, where the purpose is to look into conformity of the SUT to a given specification. The SUT is a “black box” in the sense that we do non hold a theoretical account of it, therefore, can merely trust on its discernible input/output behaviour.
Real clip is measured by quantitative usage of clock ( existent clock ) [ 1 ] .Whenever we quantify clip by utilizing the existent clock we use existent clip. A system is called existent clip system when we need quantitative look of clip to depict the behaviour of the used system. In our day-to-day lives, we rely on systems that have implicit in temporal restraints including avionic control systems, medical devices, web processors, digital picture entering devices, and many other systems and devices. In each of these systems there is a possible punishment or effect associated with the misdemeanor of a temporal restraint.
a. ONLINE SELF TESTING
Online self-testing is the most cost-efficient technique which is used to guarantee right operation for microprocessor-based systems in the field and besides improves their dependableness in the presence of failures caused by constituents aging.
DSM Technologies
Deep submicron engineering means, the usage of transistors of smaller size with faster exchanging rates [ 2 ] . As we know from Moore 's jurisprudence the size of transistors are doubled by every twelvemonth in a system, the engineering has to suit those Iraqi National Congresss in transistors in little country with better public presentation and low-power [ 4 ] .
III. Different Architectures used in Online Self Testing in Real Time Systems.
1.The Architecture of the DIVA Processing In Memory Chip
The DIVA system architecture was specially designed to back up a smooth migration way for application package by incorporating PIMs into conventional systems every bit seamlessly as possible. DIVA PIMs resemble, at their interfaces, commercial DRAMs, enabling PIM memory to be accessed by host package either as smart memory coprocessors or as conventional memory [ 2 ] . A separate memory to memory interconnect enables communicating between memories without affecting the host processor.

















PIM Array PIM to PIM Interconnect
Fig.1: DIVA Architecture
A package is closely related to an active message as it is a comparatively lightweight communicating mechanism incorporating a mention to a map to be invoked when the package is received. Packages are transmitted through a separate PIM to PIM interconnect to enable communicating without interfering with host memory traffic. This interconnect must back up the dense packing demand of memory devices and let the add-on or remotion of devices from system.
Each DIVA PIM bit is a VLSI memory device augmented with general intent computer science and communicating hardware [ 3 ] . Although a PIM may dwell of multiple nodes, each of which are chiefly comprised of few M of memory and a node processor.
2. Bit Multiprocessor Architecture ( CMP Architecture )
Bit multiprocessors are besides called as multi-core microprocessors or CMPs for short, these are now the lone manner to construct high-performance microprocessors, for a figure of grounds [ 6 ] .
restricting credence of CMPs in some types of systems.
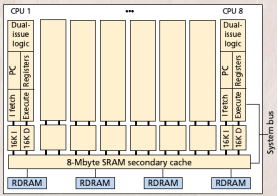
Fig.2: The above figure shows the CMP Architecture [ 6 ]
3.SCMP Architecture: An Asymmetric Multiprocessor System-on-Chip
Future systems will hold to back up multiple and coincident dynamic compute-intensive applications, while esteeming real-time and energy ingestion restraints. Within this model, an architecture, named SCMP has been presented [ 5 ] . This asymmetric multiprocessor can back up dynamic migration and pre-emption of undertakings, thanks to a coincident control of undertakings, while offering a specific information sharing solution. Its undertakings are controlled by a dedicated HW-RTOS that allows online programming of independent real-time and non existent clip undertakings. By integrating a affiliated constituent labelling algorithm into this platform, we have been able to mensurate its benefits for real-time and dynamic image processing.
In response to an of all time increasing demand for computational efficiency, the public presentation of embedded system architectures have improved invariably over the old ages. This has been made possible through fewer Gatess per grapevine phase, deeper grapevines, better circuit designs, faster transistors with new fabrication procedures, and enhanced direction degree or data-level correspondence ( ILP or DLP ) [ 7 ] .
An addition in the degree of correspondence requires the integrating of larger cache memories and more sophisticated subdivision anticipation systems. It hence has a negative impact on the transistors’ efficiency, since the portion of these that performs calculations is being bit by bit reduced. Switch overing clip and transistor size are besides making their lower limit bounds.
The SCMP architecture has a CMP construction and uses migration and fast pre-emption mechanisms to extinguish idle executing slots. This means bigger exchanging punishments, it ensures greater flexibleness and responsiveness for real-time systems.
Programing Model
The scheduling theoretical account for the SCMP architecture is specifically adapted to dynamic applications and planetary programming methods. The proposed scheduling theoretical account is based on the expressed separation of the control and the calculation parts. Computation undertakings and the control undertaking are extracted from the application, so as each undertaking is a standalone plan. The control undertaking handles the calculation undertaking programming and other control functionalities, like synchronisms and shared resource direction for case. Each embedded application can be divided into a set of independent togss, from which expressed executing dependences are extracted. Each yarn can in bend be divided into a finite set of undertakings. The greater the figure of independent and parallel undertakings are extracted, the more the application can be accelerated at runtime.






 Fig3:
Fig3:








SCMP Processing
As shown in Figure 9, the SCMP architecture is made of multiple PEs and I/O accountants. This architecture is designed to supply real-time warrants, while optimising resource use and energy ingestion. The following subdivision describes executing of applications in a SCMP architecture.
When the OSoC receives an executing order of an application, its Petri Net representation is built into the Task Execution and Synchronization Management Unit ( TSMU ) of the OSoC. Then, the executing and constellation demands are sent to the Selection unit harmonizing to application position. They contain all
of active undertakings that can be executed and of coming active undertakings that can be prefetched. Scheduling of all active undertakings must so integrate the undertakings for the freshly loaded application. If a non-configured undertaking is ready and waiting for its executing, or a free resource is available, the PE and Memory Allocation Unit sends a constellation primitive to the Configuration Unit.
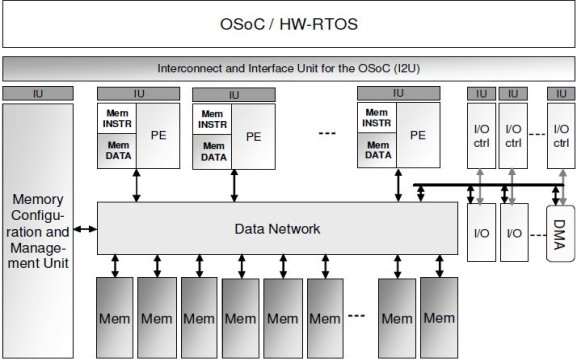
Fig4: SCMP Architecture [ 5 ]
Table Of Comparison
|
Name Of The Paper |
Year of Publication |
Writer |
Limits |
|
The Architecture of the DIVA Processing In Memory Chip |
2002 |
Jeff Draper, Jacqueline Chame, Mary Hall, Craig Steele, Tim Barrett, Jeff LaCoss, John Granacki, Jaewook Shin, Chun Chen, Chang Woo Kang, Ihn Kim, Gokhan Daglikoca |
This paper has described a elaborate description of DIVA PIM Architecture. This paper holding some issues for working memory bandwidth, peculiarly the memory interface and accountant, direction set characteristics for mulct grained parallel operation, and mechanism for address interlingual rendition. |
|
Chip Multiprocessor Architecture: Techniques to Improve Throughput and Latency |
2007 |
KunleOlukotun, LanceHammond, James Laudon |
This work provides a solid foundation for future geographic expedition in the country of defect-tolerant design. We plan to look into the usage of trim constituents, based on wearout profiles to supply more sparing for the most vulnerable constituents. Further, a CMP switch is merely a first measure toward the overreaching end of planing a defect-tolerant CMP system. |
|
SCMP Architecture: An Asymmetric Multiprocessor System on-Chip for Dynamic Applications |
2010 |
NicolasVentroux, Raphael David |
The new architecture, which has been called SCMP, consists of a hardware real-time operating system gas pedal ( HW-RTOS ) , and multiple computer science, memory, and input/output resources. The operating expense due to command and execution direction is limited by our extremely efficient undertaking and informations sharing direction strategy, despite of utilizing a centralized control. Future works will concentrate on the development of tools to ease the programmation of the SCMP architecture. |
Decision
We have done a study how online self-testing can be controlled in a real-time embedded multiprocessor for dynamic but non safety critical applications utilizing different architectures. We analyzed the impact of three online self-testing architectures in footings of public presentation punishment and mistake sensing chance. Equally long as the architecture burden remains under a certain threshold, the public presentation punishment is low and an aggressive ego trial policy, as proposed in can be applied to
[ 8 ] D. Gizopoulos et al. , `` Systematic Software-Based Self -Test for Pipelined Processors '' , Trans. on Vlsi Sys. , vol. 16, pp. 1441-1453, 2008.
such architecture. Otherwise, online self-testing
should see the programming determination for
extenuating the operating expense in hurt to blame
sensing chance. It was shown that a policy that sporadically applies a trial to each processor in a manner that accounts for the idle provinces of processors, the trial history and the undertaking precedence offers a good tradeoff between the public presentation and mistake sensing chance. However, the rule and methodological analysis can be generalized to other multiprocessor architectures.
Mentions
[ 1 ] R. Mall. “Real-time system” : Theory and pattern. Pearson Education, 3rd Edition, 2008.
[ 2 ]Analysis of On-Line Self-Testing Policies for Real-Time Embedded Multiprocessors in DSM Technologies O. Heron, J. Guilhemsang, N. Ventroux et Al2010 IEEE.
[ 3 ]Jeff Draper et al. ,``The Architecture of the DIVA Processing In Memory Chip '' ,ICS’02,June.
[ 4 ] C. Constantinescu, “Impact of deep submicron engineering on dependableness of VLSI circuits” , IEEE DSN, pp. 205-209, 2002.
[ 5 ] Nicolas Ventroux and Raphael David, “SCMP architecture: An Asymmetric Multiprocessor System-on-Chip for Dynamic Applications” , ACM Second International Forum on Next Generation Multicore/Many nucleus Technologies, Saint Malo, France, 2010.
[ 6 ] Chip Multiprocessor Architecture: Techniques to Improve Throughput and Latency.
[ 7 ] Antonis Paschalis and Dimitris Gizopoulos “Effective Software-Based Self-Test Strategies for On-Line Periodic Testing of Embedded Processors” , DATE, pp.578-583,2004.
IJSET 2014Page 1
Cite this Page
A Survey on Different Architectures Uses in Online Self Testing for Real Time Systems. (2017, Jul 09). Retrieved from https://phdessay.com/a-survey-on-different-architectures-uses-in-online-self-testing-for-real-time-systems/
Run a free check or have your essay done for you
